Friday Afternoon
There have been a few ongoing niggles that are being sorted as people discover them. If you are seeing this when you try to send in gmail…
get in touch. It seems that google has lost the connection to your outgoing mail server, it is a very easy fix.
Friday Morning
Well, the migration finished and now the resource graphs look like this, with everything settling down :o)
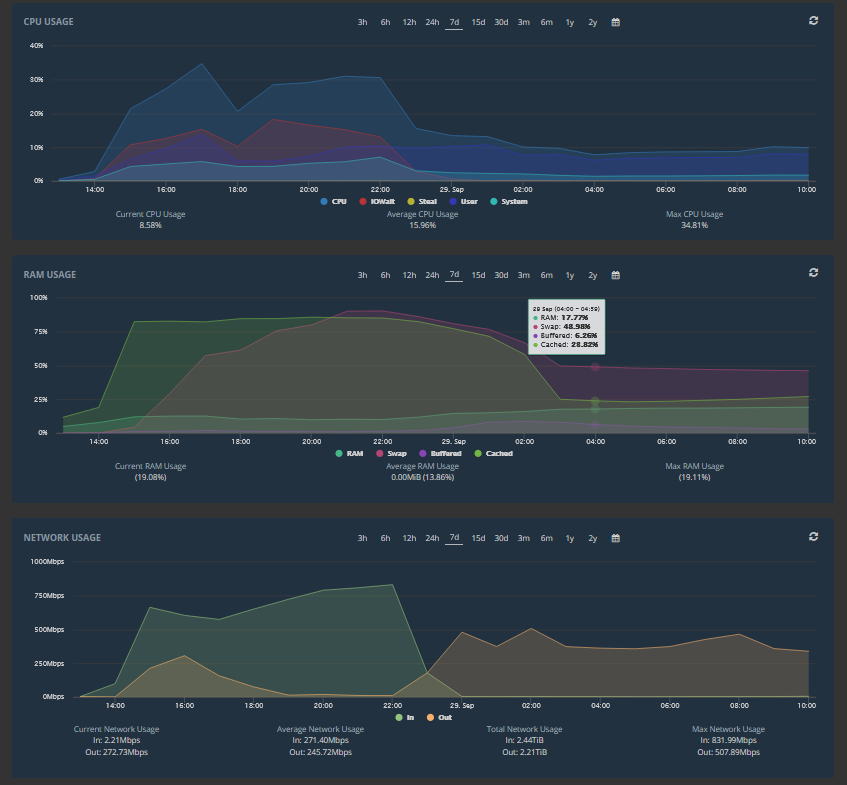
If you haven’t already, please CHECK YOUR WEBSITE. There have been a couple of instances where some things didn’t migrate properly. They are fixed really quickly, but I have to know about it.
Over the next week there will still be some fine tuning. There are a bunch of things that are different and some new things. But that is for another post to keep separate from the migration story.
Thursday 2145PM (AEST)
To the handful of people suffering a bit of pain, please be patient. The migration is at 75% and should be completed within a couple of hours. Meanwhile it is a balance between going hard to get it done quickly or stretching it out and reducing pain for some but increasing it for others.
The server is running hard at the moment – the graphs flatten because certain things like RAM usage reach a specified limit to prevent everything bogging down.
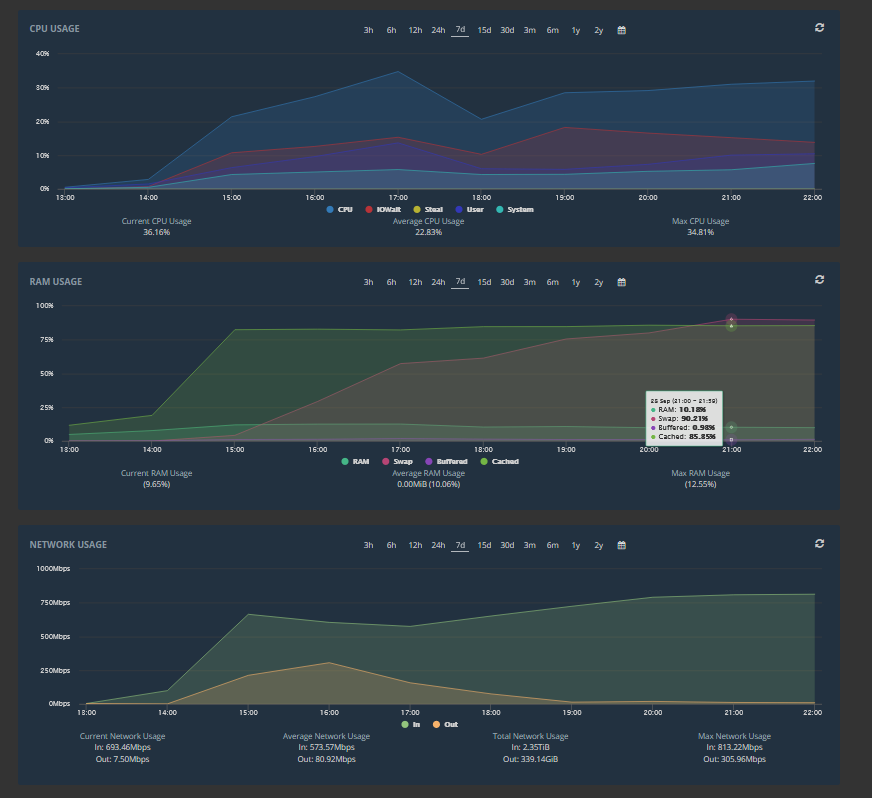
I am going to post the comparison in the morning.
Thursday 1400PM (AEST)
We have just successfully tested the first migrations. Happy Dancing here so far!
Because the old server and new server are in the same data centre, transfers are lightning fast, it will still take some time to do them all (there are a lot of accounts).
The majority of sites should be on the new server by about 1630, the bigger sites which we are leaving until last will take until about 2230.
Thursday 1230PM (AEST)
If you read my earlier post you will have an understanding of what has been happening. The migration to a new server will happen this afternoon and into the evening, it will take quite a while. There should be no downtime for any sites, but as with any technology, what could possibly go wrong?
I’ve asked them to keep me informed about the progress and I am going to update this page as often as I can.
Some people will need to be contacted to update settings, but even those sites will continue working, it is just something that will need to be done within the next couple of weeks.
IF YOUR SITE WAS WORKING AND YOU SUDDENLY NOTICE IT ISN’T, EMAIL ME but I have been assured “we have done this thousands of times and it should be fine” – what can I do except trust them/
The outcome of all this should be a stable, faster server and a more chilled Steve.
I appreciate your patience up until now. If you have any questions, fire away.
Thursday 10:30AM (AEST)
If you are a 123host customer you will know that the server has been pretty unreliable for the last week or so. There has been a bunch of brief outages and a couple of extended outages. Some of you will know because you have spotted the problem, others know from the email I sent out. Whichever you group are in, I sincerely apologise for this and offer the following without it being any way a lessening of my responsibility.
Something is going on. Between me (with help from a fellow web host), the server provider and cPanel (the operating system developers) we have spent a lot of time trying to diagnose what is going on, so far without success. What they say is happening (and I don’t necessarily agree) is that there are too many accounts on the machine and at times it runs out of memory. An inbuilt safety system then shuts down some processes to bring things back under control.
Think of it as though you are driving at night and your car battery is a little low because you have too many electrical things running, suddenly your headlights (=the website software) stop working, but your car (=the server) is still running. Your car has some smarts and it turns off the radio and some other devices (=some running processes), then turns the headlights back on again and away you go – that is a near enough metaphor. But sometimes, for some reason, it doesn’t automatically turn the headlights back on, you have top lift the bonnet and flick a switch manually.
I can’t tell you how stressful this has been. I really try to deliver up to (in excess of?) my own expectations of services I receive and this is below that.
So after probing and thinking and eventually biting the bullet, 123Host will be moving to a much more powerful server at a new provider. This isn’t through any dissatisfaction with the old one, I have been there for a number of years and am mostly happy. But they are changing the model of how they provide servers so that in future I have to manage everything – software licenses, account backups, tech fixes etc. This will mean a lot more work for me, some of it beyond my skills. I would rather pay a bit more and have people who know this stuff do the stuff I don’t know.
I am waiting for a report from the new provider after they had a poke around in the server overnight. I anticipate that over the next week all sites will migrate to the new server. For most of you it will be transparent and painless. I will have to contact a few people to update some settings, but there is no urgency, everything will keep working.
That’s all for now. I will keep updating here as I know stuff.
